Space Reporting
Space Reporting
Let's look at rocketry
We have rich datasources from government and hobby sources, which makes space datasets interesting to work with.
And a lot of people like space, so that's a bonus.
Today we'll work with data from this fantastic source:
Info
McDowell, Jonathan C., 2020. General Catalog of Artificial Space Objects, Release 1.8.0 , https://planet4589.org/space/gcat
What are we going to do?
Let's make two views; one view of where things go up (rockets), and one where things go around (satellites).
Our "where things go up view" is going to look like this, for example:
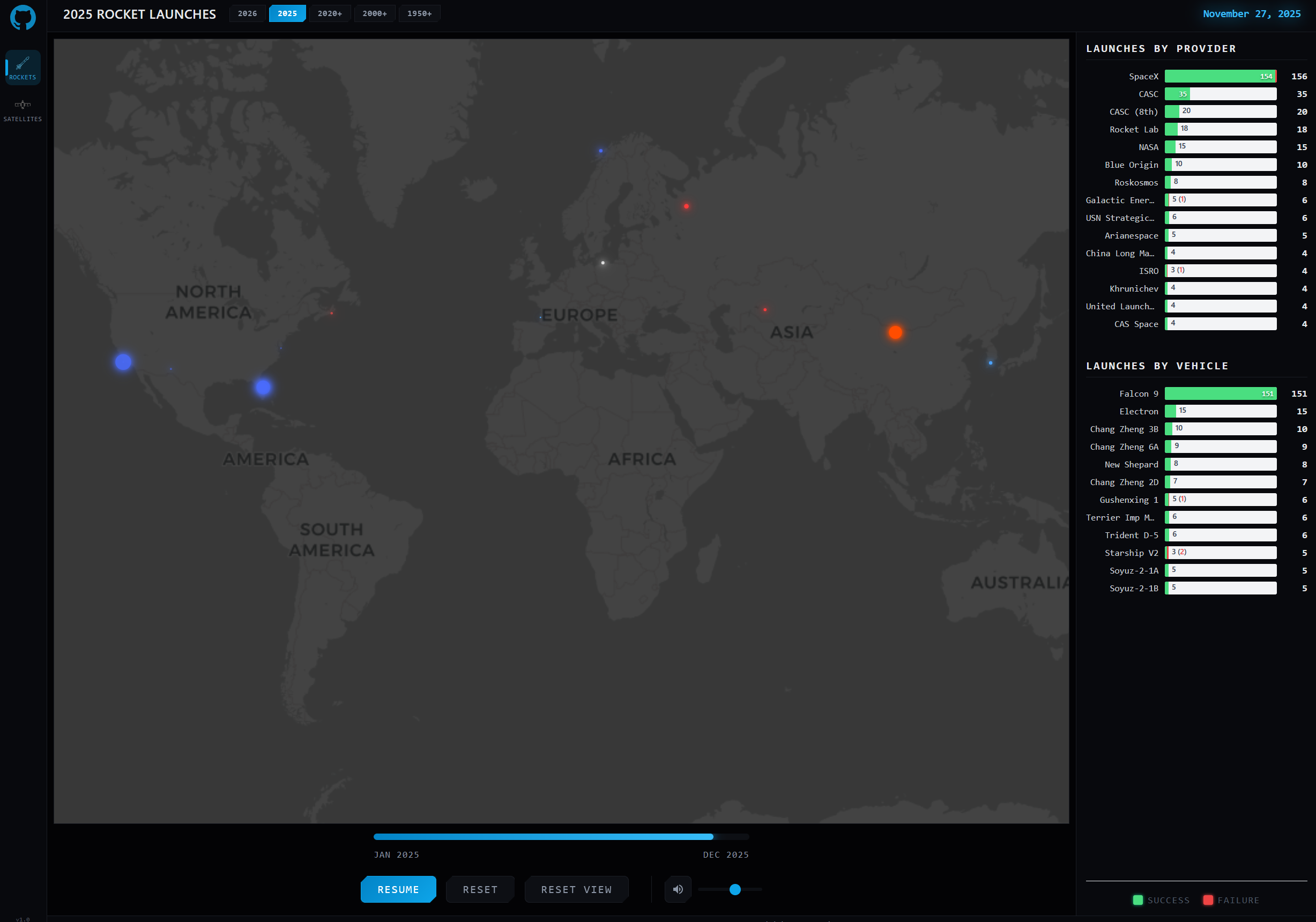
Links
If you just want to skip ahead to the final product, links are here:
Tips
Load with sound on if you can!
What's interesting?
The data is hosted on the website as a bunch of CSV files. We need to do some preprocessing to expose these as tables, and then be able to quickly iterate and extend SQL queries to create our output datasets.
DuckDB can read csv, but these files can have enough warts that it's not super resilient or safe - it's a lot easier to manage the processing in python.
How can we do this?
We'll use the duckdb shell extension to expose python scripts written in uv style directly to duckdb, following this model.
Tips
uv is a fast Python package manager. uv scripts embed their dependencies directly in the file header, making them self-contained and reproducible without a separate requirements.txt.
An example script to ingest satellite data looks like this - we've delegated most of the work on processing the CSV into the arrow format we want to a shared helper. The .tsv is actually the full remote path on the server.
#!/usr/bin/env -S uv run
# /// script
# requires-python = ">=3.13"
# dependencies = ["pyarrow", "requests"]
# ///
from ingest_core import emit, ingest_gcat_file
if __name__ == "__main__":
table = ingest_gcat_file("tsv/cat/satcat.tsv")
emit(table)
Once we have that defined, we can define a trilogy datasource that will call that script when it needs to be resolved in a DuckDB query.
root datasource satcat_raw (
JCAT: jcat,
Satcat: satcat,
Launch_Tag: launch.launch_tag,
Piece: piece,
Type: type,
#...lots more fields...
data_update_date: data_updated_through
)
grain (jcat)
file `ingest_satcat.py`
freshness by data_updated_through;
One key callout there is the 'freshness by'. In our extraction logic we actually parse out the 'last updated through' text on the gcat homepage, and turn that into a date that is put onto the table.
Since this can be expensive in wall clock time, we don't want to hit the website every time. So we'll define some downstream sources that materialize the same fields to a parquet file in Google Cloud Storage (GCS) which we'll use for default access.
Using this, we can hook up all these sources to a generic trilogy 'refresh' command. When we run this, we'll check the root sources - hitting the website - and then the timestamps from our parquet files; if any are stale, we'll update them.
trilogy refresh data
Then we'll wire up a conditional output dump to JSON for when we do refresh, and use that JSON to serve our website!
Our daily updates then look like this - we can go ahead and schedule that in github actions, and we have an auto-updating website!
Executing directory: data | Dialect: duck_db | Debug: disabled | Config: data/trilogy.toml
Starting parallel execution:
Files: 15
Dependencies: 22
Max parallelism: 4
Strategy: eager_bfs
✓ etl.preql (1.31s)
✓ sites.preql (6.64s) [1 datasource updated]
✓ engine.preql (6.70s) [1 datasource updated]
✓ platform.preql (6.78s) [1 datasource updated]
✓ organization.preql (6.96s) [1 datasource updated]
✓ stage.preql (4.17s) [1 datasource updated]
✓ vehicle.preql (7.23s) [2 datasources updated]
✓ launch.preql (13.62s) [1 datasource updated]
✓ core_local.preql (11.40s)
✓ debug.preql (11.58s)
✓ core.preql (11.75s)
✓ satellite.preql (19.20s) [1 datasource updated]
✓ satellite_data.preql (16.09s)
✓ satellite_data_local.preql (16.32s)
✓ debug_satellite.preql (16.74s)
Execution Summary:
Total Scripts: 15
Successful: 8
Noop: 7
Failed: 0
Total Duration: 69.41s
Datasources Updated: 9
Next Steps
With the parquet files built, we can actually set up dynamic exploration. We'll cover that in a followup.