What are the worst times to post on HN?
What are the worst times to post on HN?
Hacker News (HN) is a great way to get eyes on a project. But we're pretty bad at posting on HN. There's lots of good analysis about best times to post. (seriously - it's an incredibly popular HN topic, probably because there's only so many ways you can slice the free Hn dataset).
We've got some data* - can we figure out how to do worse?
The goal of a Show HN post is usually to get visibility and feedback. We can use score as a proxy for that. So we want to optimize for the way that will produce the lowest score.
You could post on a Thursday about your project in Swift. You could post it on Christmas Day, when apparently no one has. But we’re getting ahead of ourselves - let's look at the data.
Tips
There is no attempt to provide causation, only correlation. There's also no attempts at statistical rigor here. You can do better by importing this dataset (all queries provided as examples) in Trilogy Studio and hack around yourself.
*Our Data
We're going to primarily use the BigQuery Hacker News dataset, which contains all posts since 2006.
A huge shoutout to the bigquery public data program - it's a fantastic way to make data accessible - both fun and serious. And Bigquery is a very nice engine with a forgiving free tier. (looking at you, snowflake!)
We will pull in Bigquery github data, though this data is stale. If you have a better source, please reach out! (issue on trilogy-public-data would be great).
For purposes here, we'll typically filter to the below. You can view each query for details.
type = 'story'- Titles starting with
Show HN - 2024–2025 only
- Excluded deleted/dead items
Where should you host your code?
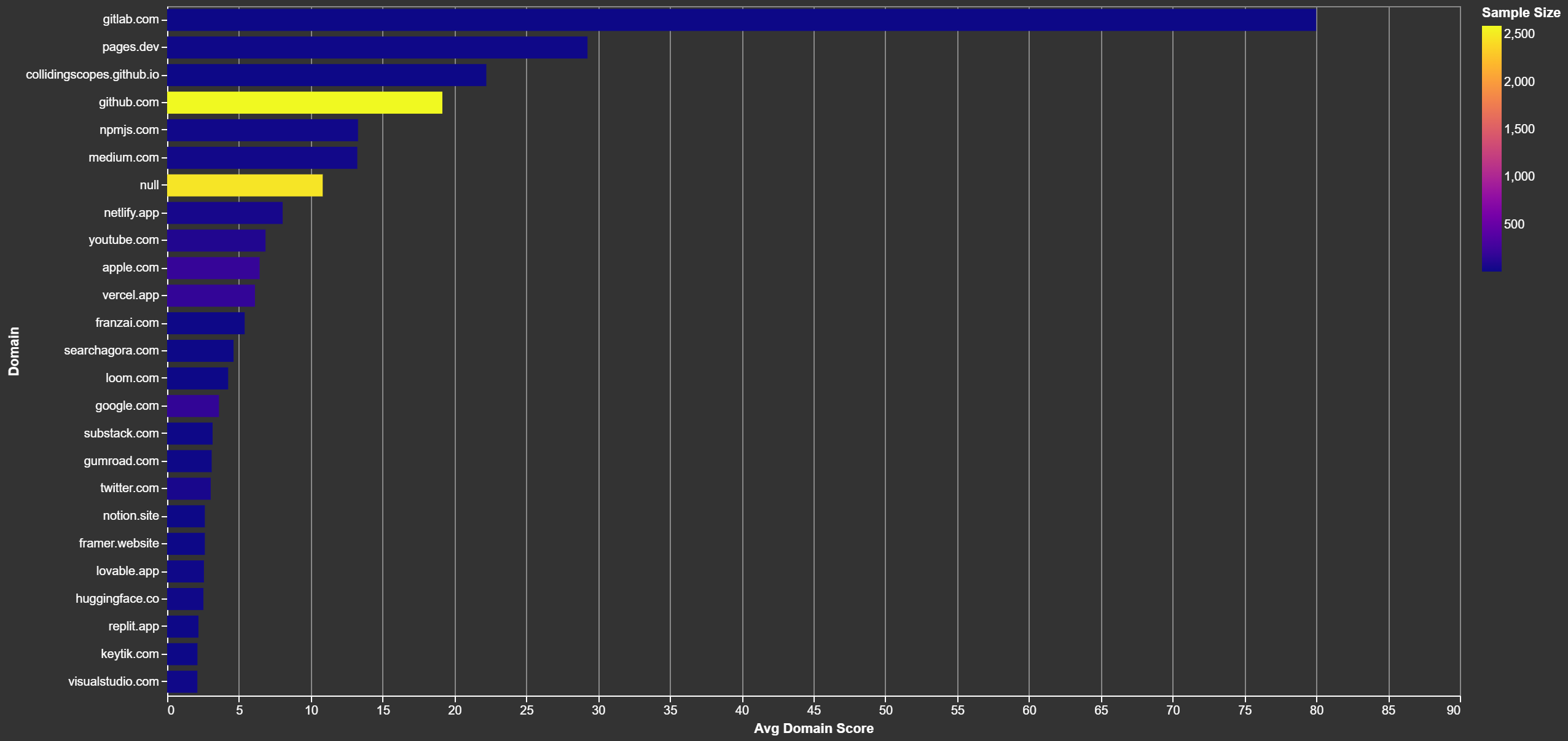
Definetely not GitLab. People upvote that a lot.
Best (Worst) Day to Post - Any Day That's Not Fool's Day?
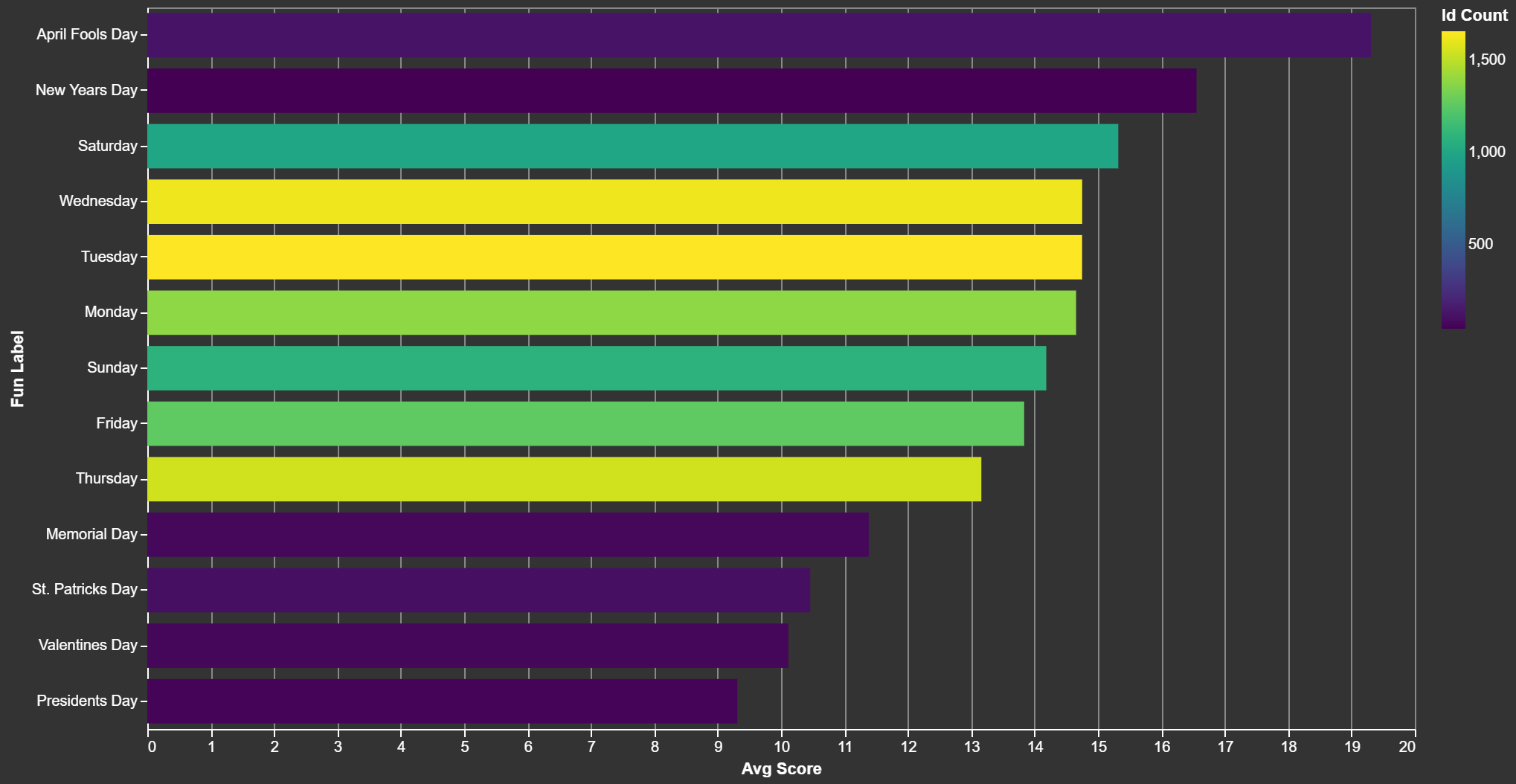
Findings:
- Presidents. People love them. Great time to post to get ignored.
- April Fools: Is your post a joke? Skip this, you might get upvotes.
- Not trying to post on holidays? Thursdays are your jam. You'll only get upvotes from the dedicated crowd.
Dead Times of Day
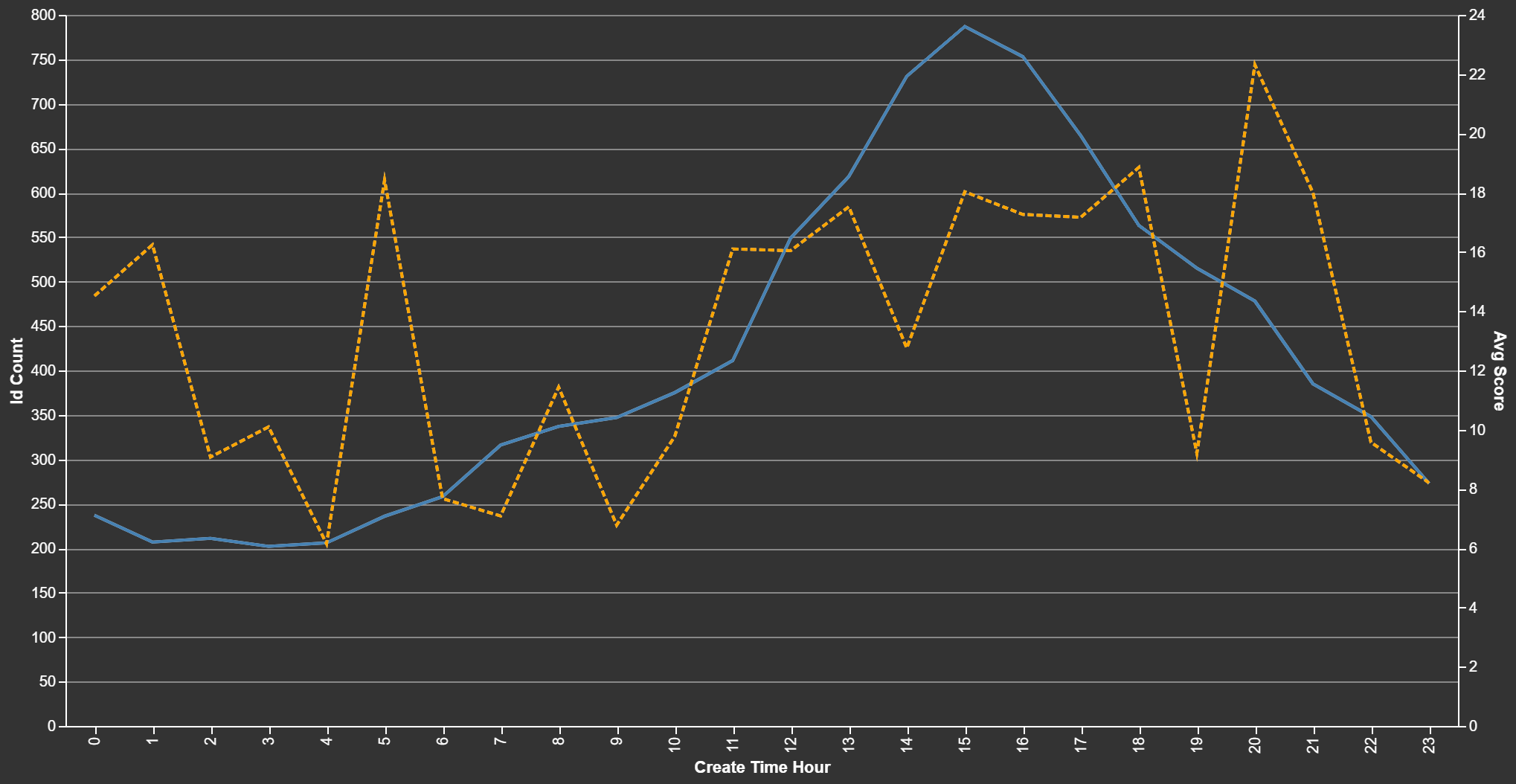
Observations:
- Honestly, no idea what to make of this.
- There's a few bad times. Pick one.
Post Length: Short Post, No Engagement
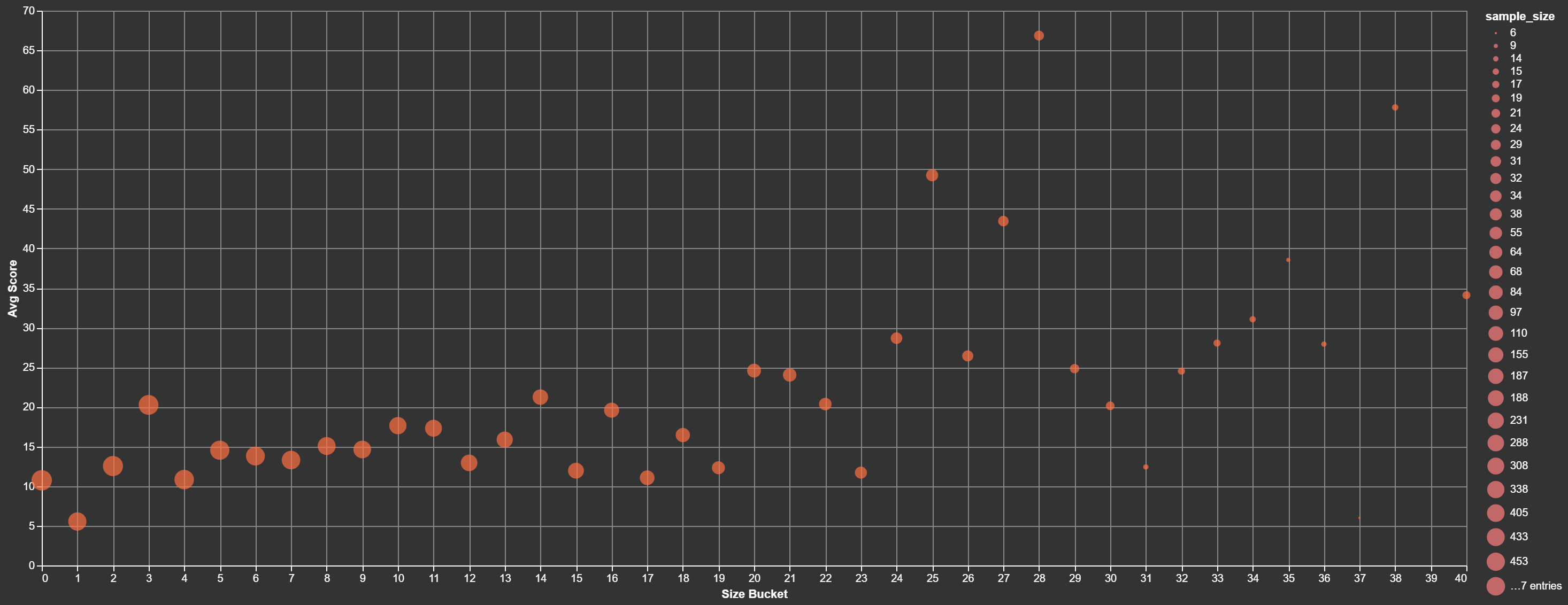
That looks like it might go up and to the right - let's call it a positive correlation with length. 0 is the classic link only.
So the sweet spot - 0-100. Keep your post brief enough, and you can avoid those upvotes!
The Non-Popular Words
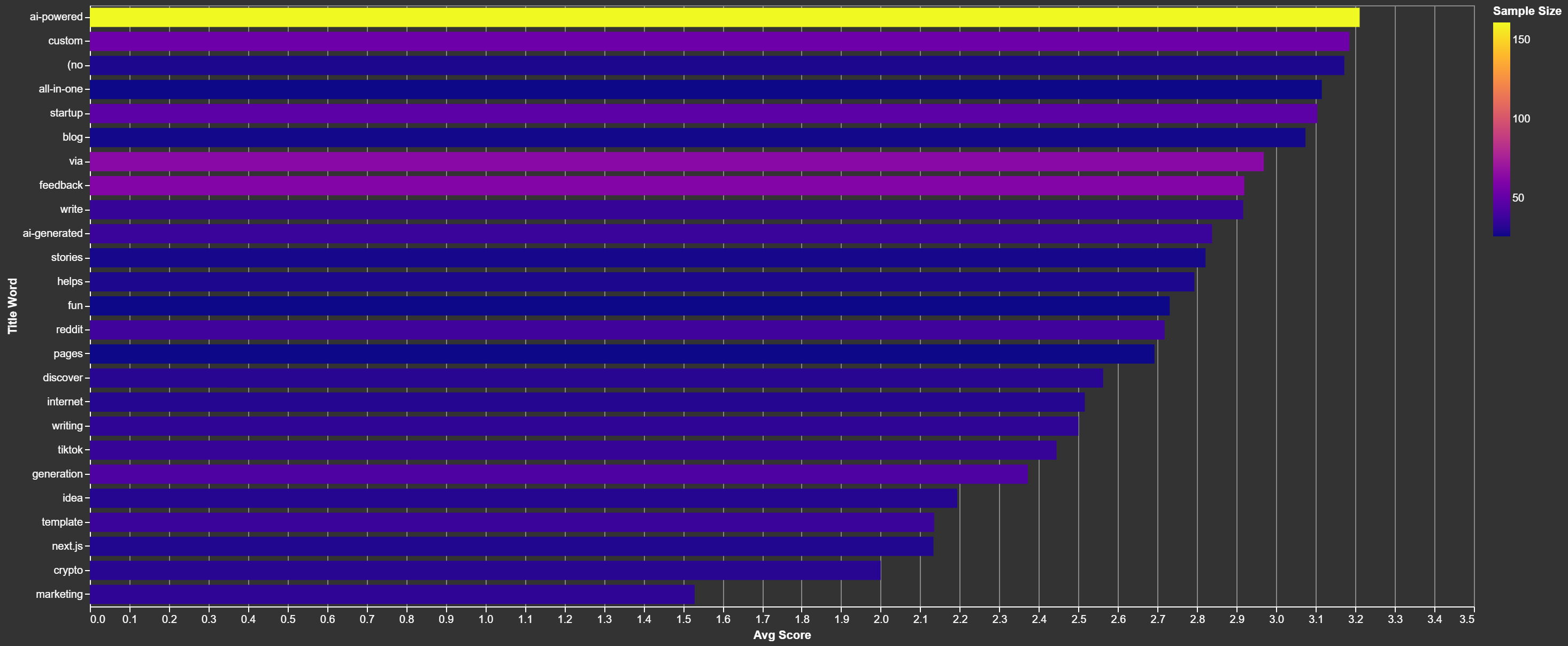
Repeat offenders:
"Marketing"- Huh, not a winner."Crypto"– Dated ideas are a good one way to avoid upvotes.
Warning
The BigQuery data used for GitHub is pretty stale, so these queries use a longer lookback - all data since 2015.
Does Your License Matter?
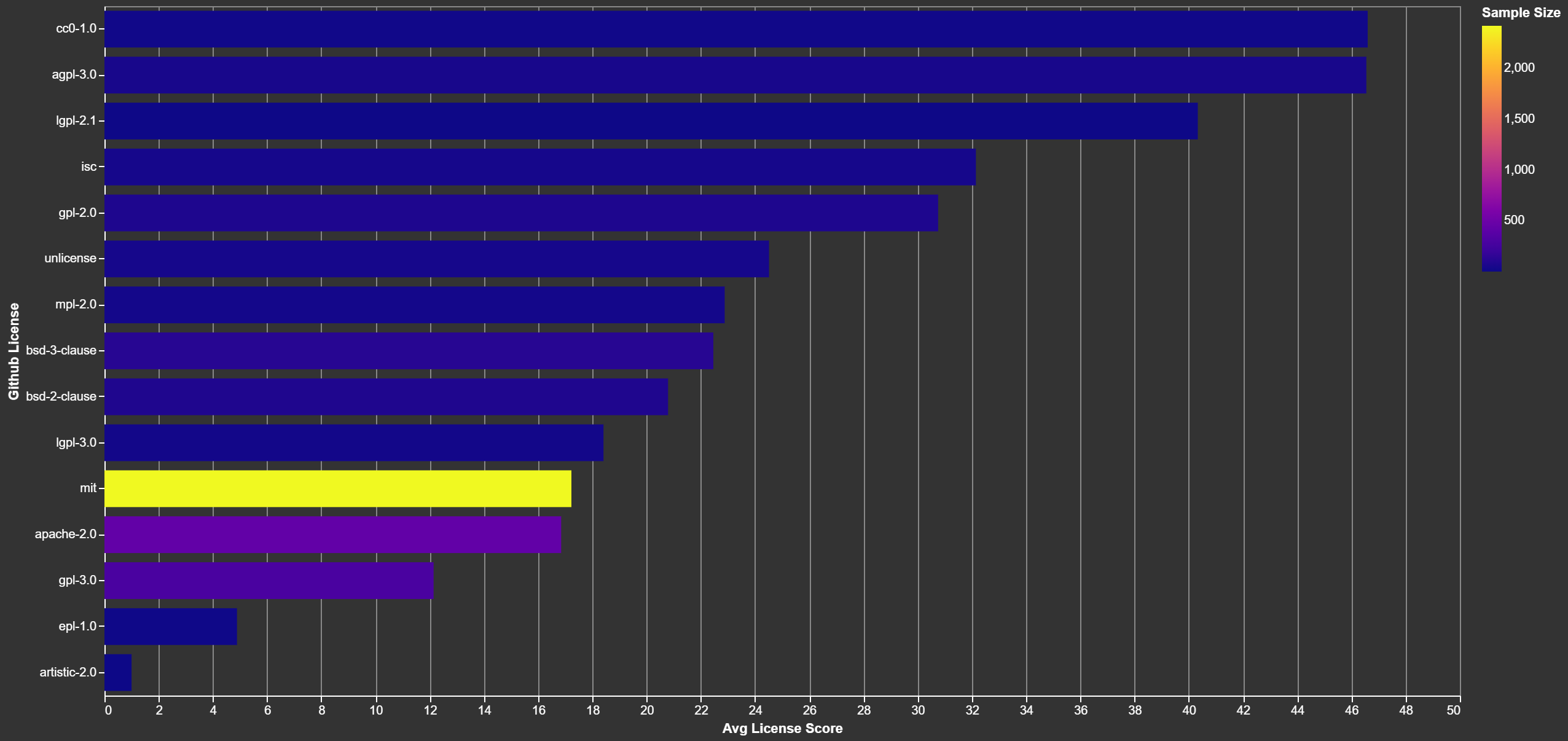
People love Creative Commons? Stay away from that.
Does Your Language Matter?
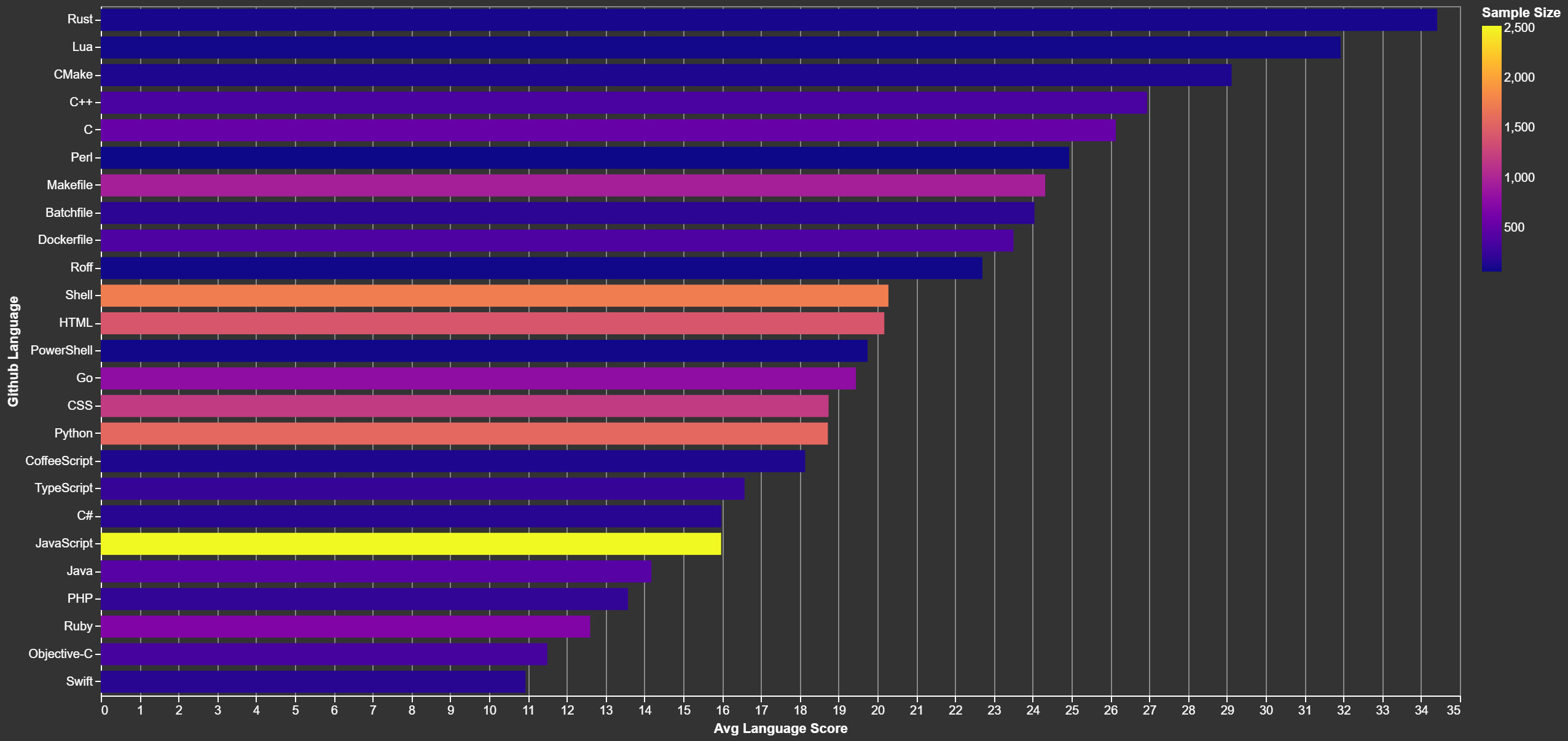
Whatever you do, don't post something related to Rust if you don't want to hit the front page. [Or AI, or the latest trend.]