Semantic Modeling in Trilogy
Semantic Modeling in Trilogy
The Semantic Model and Query Engine
Trilogy states that it has an 'inline semantic model' that supports iteration just like SQL and enables automatic query resolution. What is it, actually?
It consists of 3 key statements that produce semantic effects. These are just like any other trilogy statement - they are run in inline, so you can iteratively create, define, and extend a model.
There is not a difference between the semantic language and the query language - think of it like DDL vs Select in SQL.
Theory
There are many detailed technical analysis of SQL and how to category theory and relation algebra. Trilogy is inspired by many of those, but takes a practical, pragmatic approach to the model - you don't need to know any theoretical underpinnings to follow.
The core idea is a virtual database. In this virtual database, every field can be addressed by a unique combination of other fields.
For example, a customer table might have a customer id, name, address, etc. The customer id - if a primary key - is the unique identifier for the other fields. When you get a new customer, you get a new ID.
The name and address are 'properties' - they represent attributes that exist only because of the unique identifier. If you get a new customer, you may not get a new address or name - they might have the same name as an existing customer.
At query time, we resolve all selected fields and produce a grain. The grain represents the unique combination of identifying keys. If a property is in the select, and all of its key fields are, the property can be dropped from the grain - it provides no additional information. If the property keys are not in the grain, then the property is implicitly promoted to a key for query resolution.
Tips
select customer.name; has a grain of customer.name; select customer.id, customer.name, customer.address has a grain of just customer.id.
Aggregates can also have grains; you can select customer.id, count(customer.id) by customer.name->same_name_customers in a query. The principle is identical. Aggregatiosn without an explicit grain take the grain of the query as a whole.
This logical database can then be mapped to a physical database; it doesn't actually matter if all those fields are in one table. The name and addresses could be split into other tables; as long as those tables have a customer.id key, they can be combined as needed to resolve a query.
When we run a query, we recursively resolve each "concept" in the output select by creating a physical instantiation of the portion of the logical model required to run, and zip these together into a final query after performance optimization.
Syntax
We'll now explore how to actually define these concepts.
Concept Declaration
Concepts are the key unit. They have a name, a type, and optionally a dependent relationship with other concepts.
Keys
The core declaration is a key.
key order_id int;
Properties
We can imagine an order id uniquely identifies an order, but there are other things about an order we might want to know.
Those are called properties.
Property declarations have a set of dependent keys assigned before the name name - <key1,key2...>.<name>.
Tips
Brackets are optional when you have a single key - <key1>.val and key1.val will be treated the same
property order_id.product string;
property <order_id>.placed datetime;
property order_id.revenue float;
A property defines a dependent relationship that will be used for aggregation and simplification. If we say every order has a revenue, if we try to get order revenue, we first need to get a set of rows with one order_id and one revenue value per row, before we aggregate.
We can also drop revenue from inferred joins if order_id is present.
Types and the Standard Library
Trilogy includes a standard library which comes with helpful functions and types for common use cases. IDEs and display tools can integrate with these types to provide richer experience.
import std.geography; # import latitude/longtidue
key store_lat float::latitude;
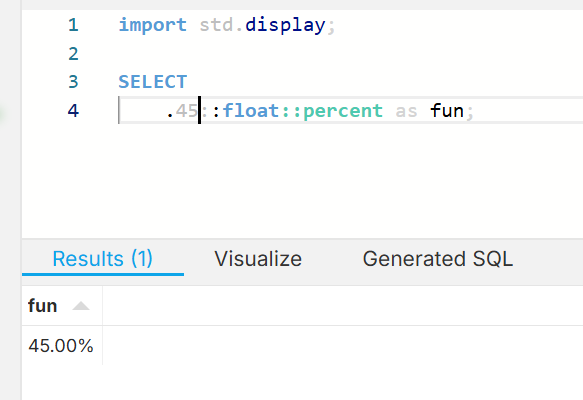
An example of an editor automatically formatting display based on the percent type:
Derived Concepts (Transformations)
Transformations represent a derivation of a new concept from other concepts. They should use the keyword auto, and the compiler will determine their type.
auto product_revenue_rank <- rank product by sum(revenue) by product desc;
Constants
Constants are a special subset of transformations where the right side is a static expression. They can undergo additional optimization.
const meaning_of_life <- 49;
Datasources
Datasources define where we get data from. They are the inputs to the resolution graph. Typically they will be tables in a database, though they can also be queries.
A datasource has a name, a mapping of columns on the asset (physical names) to concepts, a grain (the PK of the table, expressed as concepts), and a physical database address.
datasource order_data
(
ord_id:order_id,
ord_rev:revenue,
)
grain (order_id)
address orders;
To use a query - useful for testing - you replace the 'address' with a 'query'.
datasource
(ord_id:order_id,
ord_rev:revenue,)
grain (order_id)
query '''
SELECT
1 as ord_id, 1.23 as ord_rev
UNION ALL
SELECT
2 as ord_id, 4.0 as ord_rev
'''
;
Merge Statements
Merge statements let you merge one concept into another. This can either be used to bridge two models or to express synonym relationships.
For example
key number int;
key number_size string;
key _number_size <- len(number::string);
merge _number_size into number_size;
Functions
Functions allow creating reusable code factories.
For example, the std lib definds a calculate percent function:
def calc_percent(a, b, digits=-1) ->
case
when digits =-1 then
case
when b = 0 then 0.0::numeric
else (a/b)::numeric
end
else round((
case
when b = 0 then 0.0::float
else (a/b)::float
end
)::numeric, digits)
end::numeric::percent;
They are parsed and called with the @ prefix.
SELECT
@calc_percent(40.56, 100, 1);